Core contributor to Qwen Image 2.0, 3.0, and Turbo foundation model iterations.
MPhil Student @ HKUST(GZ)
Zikai Zhou
I am an MPhil researcher at HKUST(GZ), working on generative AI, efficient sampling, and visual foundation models. My research focuses on diffusion and flow-matching sampling, inference acceleration, video generation, and data-centric model improvement.
Gold Reviewer, Top 25%.
Golden Noise accepted at ICCV and cited 103 times on Google Scholar.
Research
Efficient generation from algorithms to data flywheels.
Sampling and acceleration
Designing faster and more reliable sampling procedures for diffusion, flow matching, and masked generative transformers.
Data-centric generation
Building dataset condensation, filtering, distillation, and evaluation pipelines that close the loop between user signals and model training.
Video and image foundation models
Developing T2V, I2V, V2V, and text-to-image systems with stronger fidelity, controllability, and production readiness.
Evaluation pitfalls
Studying where generative evaluation breaks, including guidance, benchmark design, and automated pre-training feedback.
Publications
Research papers and technical reports

Qwen-Image-2.0-RL Technical Report
Presents a reinforcement learning and on-policy distillation post-training pipeline for Qwen-Image-2.0, improving generation quality, instruction following, and image editing accuracy.

Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
Introduces Qwen-Image-Agent, a context-centric framework that plans, reasons, searches, uses memory, and incorporates feedback to bridge underspecified real-world requests and sufficient generation context.

Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
Introduces Qwen-RobotWorld, a language-conditioned video world model for embodied intelligence, targeting robotic manipulation, autonomous driving, indoor navigation, and language-guided planning.
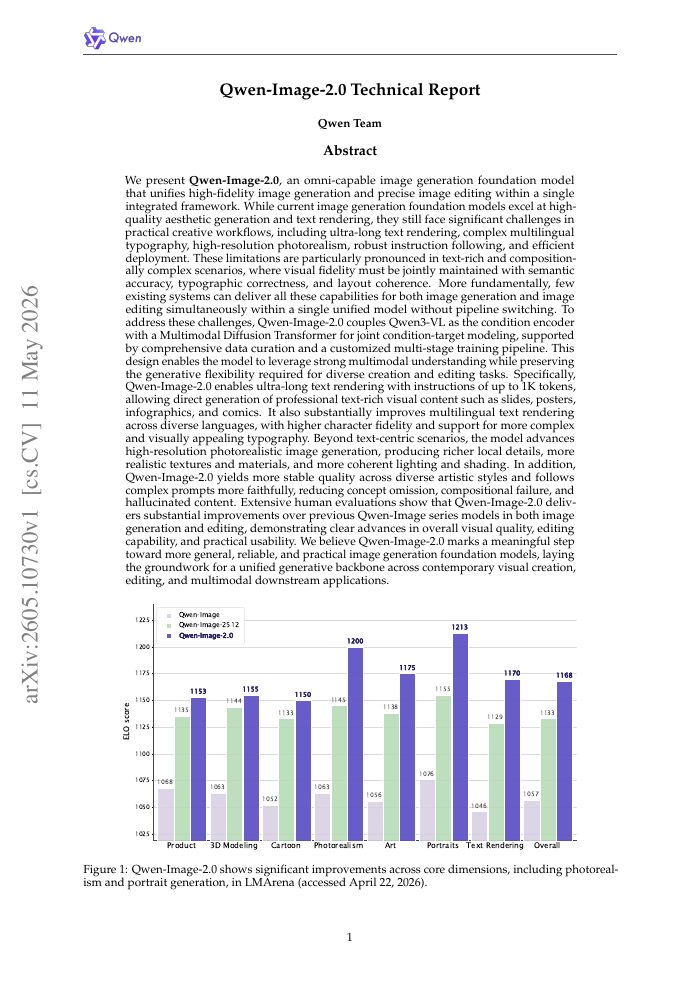
Qwen-Image-2.0 Technical Report
Documents the second-generation Qwen Image foundation model, including model iteration, data construction, training, and evaluation practices for large-scale text-to-image generation.

Qwen-Image-VAE-2.0 Technical Report
Presents the visual autoencoding component behind Qwen Image, focusing on compact visual representation, reconstruction quality, and downstream generation fidelity.

Qwen-Image-Flash: Beyond Objective Design
Introduces a fast Qwen Image variant that emphasizes practical responsiveness while maintaining visual quality and instruction-following behavior.

Qwen-Image-Bench: From Generation to Creation in Text-to-Image Evaluation
Builds an evaluation suite for modern text-to-image models, moving beyond simple generation quality toward creative instruction following and practical creation scenarios.

Optimizing Few-Step Generation with Adaptive Matching Distillation
Studies how to distill generation trajectories into a small number of sampling steps through adaptive matching, targeting fast inference without sacrificing image quality.

Lightning Unified Video Editing via In-Context Sparse Attention
Uses in-context sparse attention to unify video editing operations in a faster pipeline, improving edit consistency while reducing unnecessary attention computation.

Exploring Data-Free LoRA Transferability for Video Diffusion Models
Examines whether LoRA modules can transfer across video diffusion models without access to the original training data, clarifying when lightweight adaptation remains reusable.

PISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers
Proposes piecewise sparse attention for diffusion transformers, aiming to retain global generation quality while spending attention only where it matters.

Improved and Accelerated Text-to-Image Generation with Collect, Reflect, and Refine
Builds a closed-loop generation framework that collects feedback, reflects on failure modes, and refines outputs to improve and accelerate text-to-image generation.

Guidance Matters: Rethinking the Evaluation Pitfall for Text-to-Image Generation
Shows that guidance choices can distort text-to-image evaluation, motivating evaluation protocols that avoid misleading comparisons across models.

Diffusion Dataset Condensation: Training Your Diffusion Model Faster with Less Data
Condenses diffusion training data so that models can learn efficiently from smaller, more informative synthetic subsets.

Golden Noise for Diffusion Models: A Learning Framework
Introduces a learning framework for finding stronger initial noise patterns, improving diffusion generation by optimizing the starting point of the sampling process.

IV-Mixed Sampler: Leveraging Image Diffusion Models for Enhanced Video Synthesis
Combines image diffusion priors with video sampling to improve visual fidelity and temporal generation in video synthesis.

Zigzag Diffusion Sampling: The Path to Success Is Zigzag
Explores a non-monotonic sampling path where diffusion models can self-reflect during generation, improving sample quality through zigzag refinement.

Exploring the Design Space for Inference Enhancement and Acceleration of Masked Generative Transformer
Systematically studies inference design choices for high-resolution masked generative transformers, identifying practical levers for quality and speed.

Reflective Flow Sampling Enhancement
Extends reflective sampling ideas to flow-based generation, targeting stronger sample quality through intermediate trajectory correction.

Elucidating the Design Space of Dataset Condensation
Maps the main choices in dataset condensation and clarifies how different recipes influence downstream training performance.

Rethinking Centered Kernel Alignment in Knowledge Distillation
Revisits CKA as a distillation signal and analyzes how representation alignment should be used for more effective teacher-student learning.

Enhancing Adversarial Attacks: The Similar Target Method
Improves adversarial attack construction by selecting similar target classes, making perturbation objectives more effective and semantically grounded.

AFN: Adaptive Fusion Normalization via an Encoder-Decoder Framework
Proposes an encoder-decoder normalization framework that adaptively fuses feature statistics for more flexible representation transformation.
The Blessing of Smooth Initialization for Video Diffusion Models
Studies how smooth initialization can stabilize video diffusion generation and improve temporal coherence at inference time.
* Equal contribution. Technical report entries reflect the Qwen Image series contributions listed in the CV and Google Scholar profile.
Experience
Research that ships into model systems.
Research Intern, Qwen Image Foundation Model Team, Alibaba Group
Core contributor to Qwen Image 2.0, 3.0, and Turbo. Built automated data flywheels, large-scale distillation pipelines, and pre-training evaluation systems for image foundation models.
Algorithm Engineer, Fuguang AI
Led R&D and deployment of T2V, I2V, and V2V models, including data collection, auto-labeling, quality assessment, inference optimization, and prompt-engineering modules.
Research Assistant, xLeaf Lab, HKUST(GZ)
Worked on AIGC inference acceleration and sampling optimization for diffusion and flow matching, contributing to Golden Noise and Zigzag Diffusion Sampling.
Education
HKUST(GZ) and BIT
MPhil student in Artificial Intelligence at HKUST(GZ), supervised by Prof. Zeke Xie. B.Eng. in Computer Science from Beijing Institute of Technology, Outstanding Graduate 2025.
Academic Service
Reviewer and chairing
ICML 2026 Gold Reviewer. Session Chair at IJCAI 2024. Reviewer for ICML, NeurIPS, ICLR, CVPR, ICCV, ECCV, AAAI, ACM MM, and IJCAI.
Talk
Inference optimization
Invited by Qingke Community to present research on inference optimization for diffusion models.